Anatomy of Frankenstein’s 2, part 1: Pages and Projects
Or: an appetizer to using sed to create bash commands.
Short recap:
Frankenstein’s ___.sh is a static website generator written
in bash, that uses multimarkdown and the usual Unix text
manipulation utilities to generate the commands that generate the
website. It relies heavily on the ‘|’ (pipe) operator to avoid
explicit for loops and variables, environmental or otherwise.
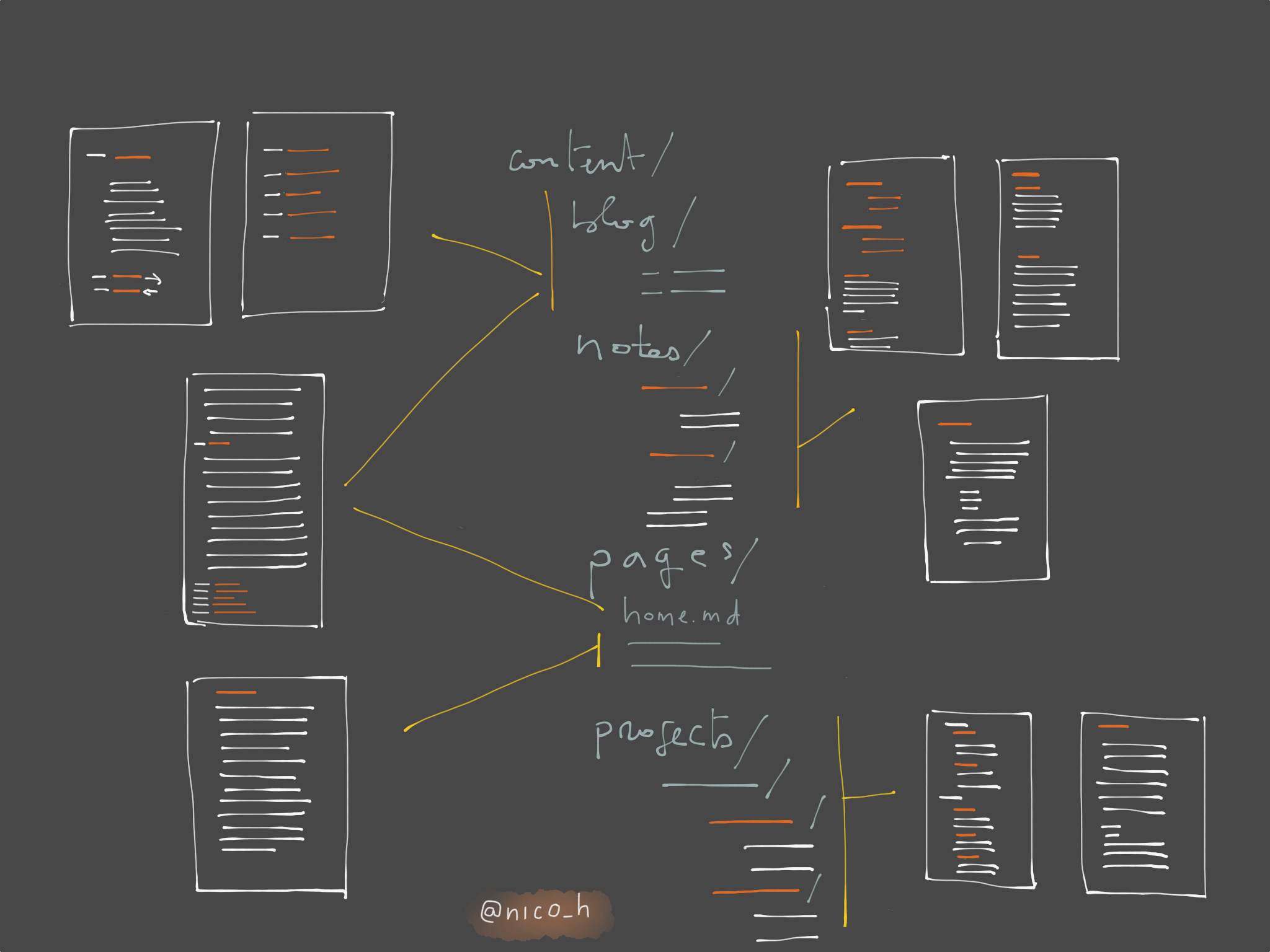
It generates content in 4+1 different fashions: blog, notes, projects, standalone pages and the homepage.
As promised in my last post, I’ll explain the some details of each type of content supported by the engine. I’ll start with the simplest1 ones: standalone pages and project pages.
Context & mechanisms
All the raw content documents are assumed to be in
(multi)markdown. The first line of each document post is assumed to be
the title, prefixed with at most a few #. Use of # as an elements of
the title of the post is discouraged as all # are removed when the
title is prepared for use as the html header (<title>) of a page.
The navigation elements in the _nav.html file use the class [name]
nohl. This allow the easy highlighting of the current section by
replacing [name] nohl with [name] highlighted. The name of the
different section is used (blog, projects, notes) as well as the filename
of the simple pages.
Most of Frankenstein’s ___.sh work by (ab)using sed and the |
operator. Most commands start by listing some files and feeding them
to sed, which will transform each filename into a list of commands
that create an html page.
Prototypical example:
ls *.md | sed -E 's:(.*).md:cat ../_header.html > \1.html; multimarkdown & >> \1.html; cat ../_footer.html >> \1.html: | bash
The | operator is placed betwen two programs, and allow the program
on the right to use output of the program on the left as input. You
can chain | operators to more than two programs (e.g.: A|B|C|D), but
obvioulsy each program will only receive the output of the previous
prgram in the chain. As the ls *.md command will find all
markdown files in the current directory, it will then feed their name
to the sed command. Then the output of sed will be given to
bash, a Unix shell, which will treat that output as a sequence of
command.
Here are the relevant extract of the sed man page:
-E: “use extended regular expression”. So I can use(.*).mdwithout escaping the parenthesis.'s:regexp:replacement:': “Substitute the replacement string for the first instance of the regular expression in the pattern space.”\1(and\2,\3…): the value of the matched element (the parts in between(and `)` in the regexp), to be used in the replacement part.&: in the replacement part, it will be “replaced by the string matching the RE”.
Other notes:
>vs>>:>will overwrite a file whereas>>will add content to it.
Thus, in our protoypical example, the sed transformation would
expand a file named “colophon.md” into this:
cat ../header.html > colophon.html; multimarkdown colophon.md >> colophon.html; cat ../footer.html >> colophon.html
The above line is then executed by bash.
This is the pattern that is used throughout ___.sh, often using
sed within the replacement of a sed pattern (but not
deeper). Schematically, this is what the page will end up looking
like:
[_header.html]
* title *
{_nav.html}
* content *
[_footer.html]
And here is the meaning of the various decoration:
[_header.html]: file included verbatim.* something *: element extracted from the source document(s).{_nav.html}: the navigation file, with the page or section highlighted if present.
Standalone pages

They are the simplest pages. They need to be in the content/pages/
folder (subfolders are ignored). They have to be named
[name].md. The name part will be used to highlight the page in the
navigation if it is present in the _nav.html.
The full line used to generate the standalone pages, in its raw glory, is this:
ls *.md | sed -E 's:(.+).md:cat ../_header.html > \1.html; head -n 1 \1.md | tr -d "#" >> \1.html ; sed "s%\1 nohl%\1 highlighted%" ../_nav.html >> \1.html ; sed -E "1 s%^([#]*) (.*)$%\\1 [\\2](/pages/\1.html)%" & | multimarkdown >> \1.html; cat ../_footer.html >> \1.html:'|bash
Clear and simple, isn’t it?
Let’s explain it a bit:
– List all the markdown files in the pages folder.
ls *.md |
– Obtain the filename for use in the following text (as \1).
sed -E 's:(.+).md:
– Create an html file with the same name, containing _header.html
cat ../_header.html > \1.html;
– Append the cleaned title of the file (it will appear as part of the title of the web page).
head -n 1 \1.md | tr -d "#" >> \1.html ;
– Add the navigation and highlight the page.
sed "s%\1 nohl%\1 highlighted%" ../_nav.html >> \1.html ;
– Transform the text part of the first line of the page into a link (see “extra” bellow).
sed -E "1 s%^([#]*) (.*)$%\\1 [\\2](/pages/\1.html)%" &
– Feed the resulting text to multimarkdown for transformation into the html page.
| multimarkdown >> \1.html;
– Add the common site _footer.
cat ../_footer.html >> \1.html:'
– Feed all of generated command the above to bash to execute it.
|bash
There is an extra trick used in this command generation: to transform
the title of the page into a link, I wrap the text part of the title
in a markdown link. To this effect, I added an extra sed
transformation that extract, from the first line of the source page,
the header indicator:
- The
1insed -E '1 s%...means to only execute this replacement on the first line of the document. - As the
sedexpression on that line is already in asedreplacement expression, we need to escape the occurences of the match extracted in the first part of thissedexpression, this we add an\` before each value marker:\1&\2, so they are only evaluated when this expression is run bybash`.
Projects
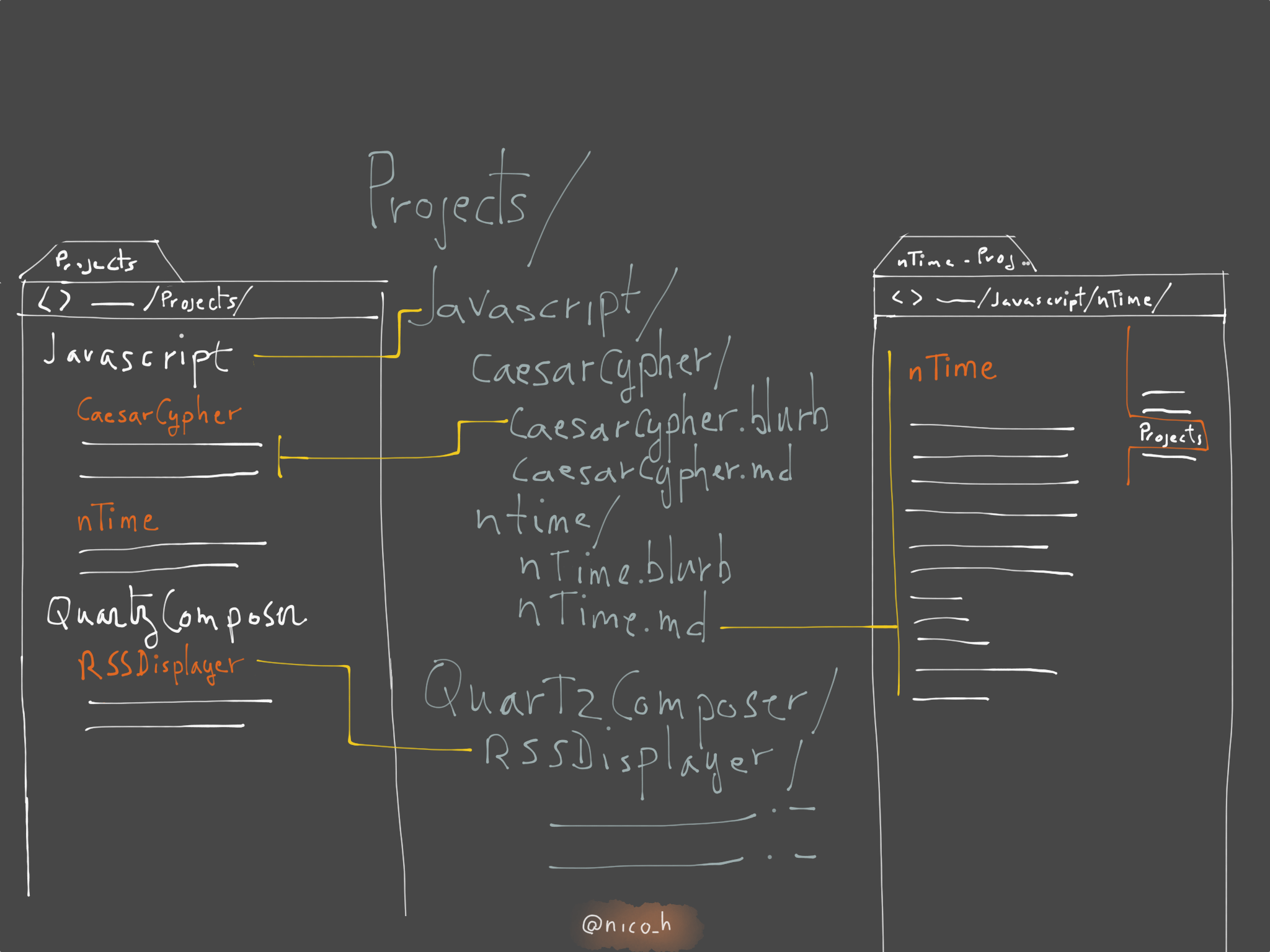
The project page is supposed to show the list of projects I’ve been working on, with a short blrub under each. The project name should link to an expanded presentation. The projects should be grouped by some category.
So I came up with the idea that the blurb and the full presentation of the projects would be different files, using the same name as the project2. Each project is in a category folder. To simplify the link creation, the blurb don’t contain any title, using the directory name of the project instead3.
Projects are organized like so:
Projects/
Category/
Project0/
Project0.blurb
Project0.md
project1/
project1.blurb
project1.md
The .blurb files will be displayed on the master “Projects” index
page, grouped by category, with a link to each project’s page. The
individual project page is created from the .md. Whitespace in the
project directory or filenames will cause that project’s pages to
not be generated correctly (non-ascii filenames are untested).
The project pages are create in 3 steps:
- Group each category’s blurb in the same file, with markdown links to each project.
- Create the project index page by assembling the category blurbs together.
- Create the individual project pages.
1) Grouping
– To generate the Projects index page, get each blurb.
cd content/projects; ls */*/*.blurb |
– Grab the (category)/(project)/(blurb) as \1, \2 & \3.
sed -E 's:.\/(.+)\/(.+)\/(.*):
– Create a markdown title and link for each project, and add it to the category’s blurb collection.
echo "### [\2](\1/\2/)" >> \1.lang;
– Add each blurb to the (category) blurb collection.
cat \1/\2/\3 >> \1.lang;
– Add a newline after each blurb, so the markdown transformation doesn’t get confused, and feed the resulting commands to bash.
echo "" >> \1.lang
:'
| bash
Projects blurbs are now grouped by category.
2) Assembly
Then each category blurb list is added to the same index.txt markdown file,
separated by the category’s name (without link):
ls *.lang |
– Get the category’s name.
sed -E 's:(.*).lang:
– Add it as a markdown title to the index page.
echo "## \1" >> index.txt;
– Add the category’s blurbs to the index page.
cat \1.lang >> index.txt
:'
| bash
The next step is to transform this newly created index.txt into the
projects folder index page, with a navigation highlighting the correct
category:
– Re-create the Projects index.
cat ../_header.html > index.html;
– Set the page title to “Projects”.
echo "Projects" >> index.html;
– Higlight the ‘projects’ navigation item.
sed "s%projects nohl%projects highlighted%" ../_nav.html >> index.html
– Expand the markdown blurbs into html into the projects index page and add the footer.
multimarkdown index.txt >> index.html; cat ../_footer.html >> index.html
The global projects index page is now done.
3) Projects pages
And finally each project’s .md page is transformed into its folder’s
index page, with proper title and highlighting of the “Project”
element in the navigation section.
– So let’s get all the project md files (in category/project).
ls */*/*.md|
– Capture the (category)/(project)/(file) names.
sed -E 's:(.+)\/(.+)\/(.*):
– Create the project’s index page,
cat ../_header.html > \1/\2/index.html;
– With the project folder name as title.
echo "\2" >> \1/\2/index.html;
– Highlight the “Projects” element in the navigation.
sed "s%projects nohl%projects highlighted%" ../_nav.html
>> \1/\2/index.html;
– Transform the title into a link to the project’s folder and transform the page into html.
sed -E "1 s%^([#]*) (.*)$%\\1 [\\2](.)%" & | multimarkdown
>> \1/\2/index.html;
– Add the common footer.
cat ../_footer.html >> \1/\2/index.html
:'
| bash
All the projects html pages are now ready.
Creating of a per-category index page is left as an exercise for the reader4 ;).
Until next time
This is it for the simplest part of Frankenstein’s ___.sh. The remaining sections of ___.sh, notes, blog and the homepage, use similar technics albeit a little bit more complex as the structure of the generated pages is also more involved. I will cover them in the next post(s) on this subject.
-
That I wrote last, obviously. ↩
-
Although I could have named the files project's page and blurbs index.md and blurb.md, I decided to name them project.md and project.blurb because then it is easier to find them and make sense of them when they show up in filesystem searches (you have xxx.md & yy.md instead of index.md & index.md & index.md ….) . The category temporary file extension “.lang” is because I group my projects by the language they are written in. ↩
-
This indeed cause some discrepancies between the title on the “Projects” page and on a project‘s page if there is a white space in the project’s name. As is the case for my Displayable Creator project. ↩
-
Pull request welcome. You can add one line and change another. Hint: look at the category blurb assembly… ↩